Recurso gratuito · Manual de auditoría
Guía operativa de AI Security para LLMs.
El método que aplicamos en auditorías y testing de AI Security, abierto. Matriz de riesgos por arquitectura, scorecard de madurez y fichas técnicas con receta y mapeo regulatorio. Construido sobre el OWASP LLM Top 10 2025, pensado para CTOs, equipos de seguridad y compliance con LLMs en producción.
Vista previa
Lo que vas a recibir
Manual operativo en PDF, listo para que un equipo lo aplique sobre su propio sistema sin consultoría.

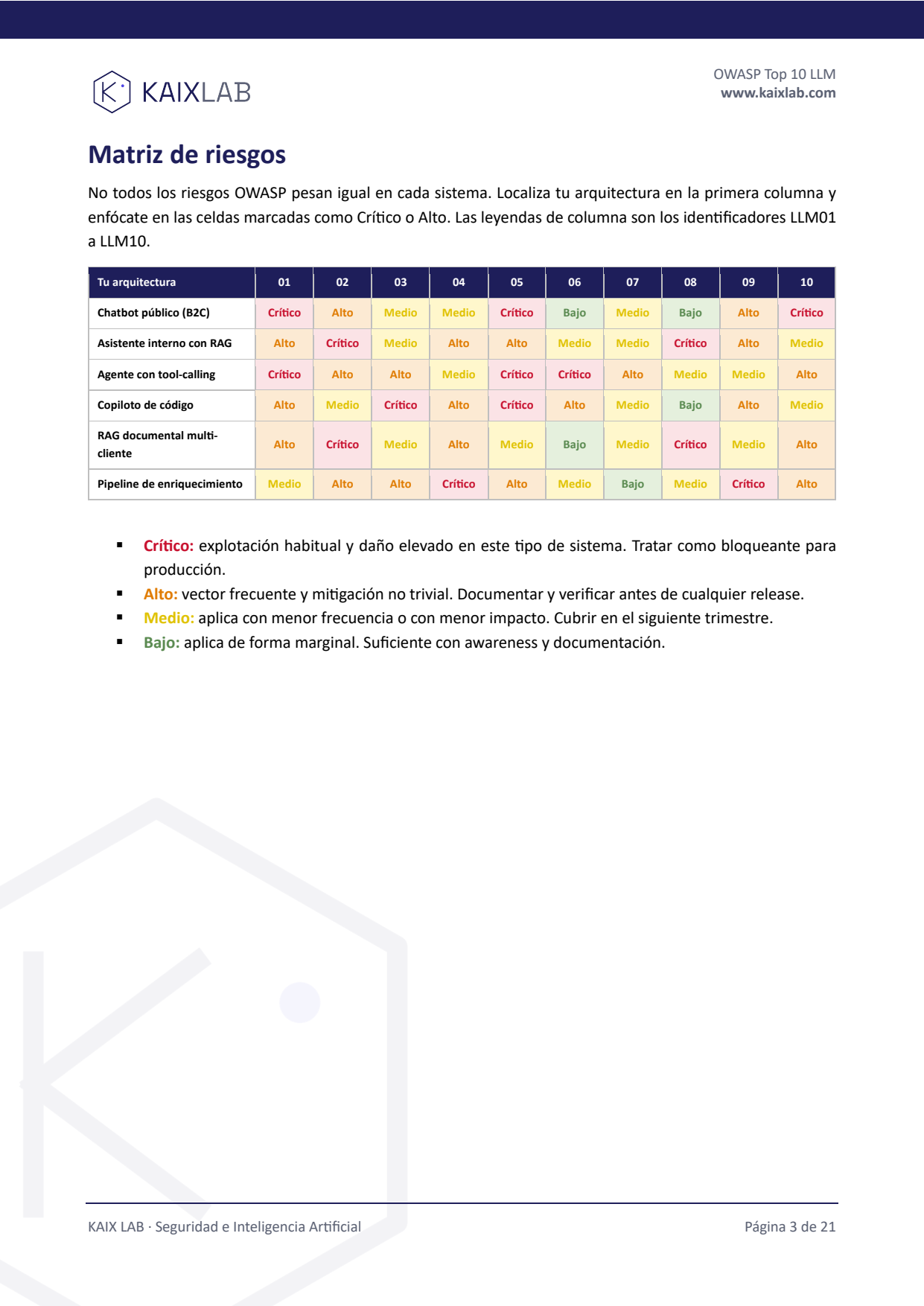

Matriz de riesgos por arquitectura
6 tipos de sistema (chatbot B2C, RAG interno, agente con tool-calling…) cruzados con los 10 riesgos. Localizas el tuyo y sabes qué priorizar.
Scorecard de madurez 0-30
10 controles auditables, puntuación 0-3 cada uno. Tres lecturas (riesgo elevado / parcial / programa establecido) y plan de acción asociado.
Fichas técnicas por riesgo (LLM01-10)
Caso real anonimizado, herramientas concretas (Garak, Lakera, Presidio, Sigstore…), config mínima, snippets de código y verificación operativa.
Mapeo regulatorio
Cada riesgo cruzado con EU AI Act, GDPR, NIS2 e ISO/IEC 42001. Más una página dedicada al marco español (AEPD, AESIA, CCN-CERT, ENS).
Qué encontrarás dentro
Manual operativo en 21 páginas
Pensado para auditar un sistema LLM en una tarde: priorizar según tu arquitectura, medir la madurez del programa, aplicar mitigaciones con código y verificar el encaje en AI Act, GDPR y el marco español.
LLM01 · Prompt Injection
Instrucciones adversarias que sobrescriben el comportamiento del modelo.
LLM02 · Sensitive Information Disclosure
Filtración de PII, secretos o contexto cruzado entre clientes.
LLM03 · Supply Chain
Modelos, datasets y plugins de origen no verificado.
LLM04 · Data and Model Poisoning
Datos de entrenamiento o fine-tuning manipulados.
LLM05 · Improper Output Handling
Output del LLM ejecutado sin sanitizar contra el sistema.
LLM06 · Excessive Agency
Agentes con permisos, herramientas y autonomía mal acotados.
LLM07 · System Prompt Leakage
Instrucciones de sistema o claves embebidas que se exponen.
LLM08 · Vector and Embedding Weaknesses
Acceso al vector store, fugas entre tenants, inyección por contenido recuperado.
LLM09 · Misinformation
Respuestas plausibles pero falsas que llegan al usuario sin verificación.
LLM10 · Unbounded Consumption
Coste y latencia sin límites: abuso, denegación económica, runaway agents.
FAQ
Preguntas frecuentes
¿Qué es el OWASP Top 10 para LLM y por qué importa?
Es la lista de los diez riesgos de seguridad más críticos en aplicaciones que usan modelos de lenguaje grandes (LLM): prompt injection, tratamiento inseguro de salidas, envenenamiento de datos, denegación de servicio del modelo, vulnerabilidades en la cadena de suministro, divulgación de información sensible, diseño inseguro de plugins, agencia excesiva, dependencia ciega del modelo y consumo no acotado. La mantiene la OWASP Foundation con aportes de cientos de profesionales y es la referencia operativa más usada en la industria para auditar y endurecer sistemas con IA generativa.
¿En qué se basa el checklist?
En el OWASP Top 10 para aplicaciones con LLM. Cada uno de los diez riesgos (LLM01 Prompt Injection hasta LLM10 Unbounded Consumption) se traduce en verificaciones binarias que un equipo de ingeniería aplica sobre su sistema en menos de una hora. Por cada riesgo hay un anti-pattern observado en producción y la pregunta que haría un atacante.
¿Qué es prompt injection y cómo lo detecto en mi sistema?
Prompt injection es el ataque más común contra LLMs: el atacante introduce instrucciones en una entrada que el modelo procesa (un mensaje del usuario, un PDF que sube, un correo, una página web que un agente navega) para que haga cosas que no debería — exfiltrar datos del prompt de sistema, ejecutar herramientas con privilegios o ignorar reglas de moderación. Se detecta combinando red teaming dirigido (inyecciones directas e indirectas), pruebas multi-turno y monitorización de salidas anómalas. El checklist marca las verificaciones mínimas para LLM01.
OWASP, MITRE ATLAS, NIST AI RMF: ¿qué framework debo usar?
Sirven para cosas distintas. OWASP LLM Top 10 es operativo y orientado a desarrolladores: «¿qué tengo que verificar en mi código?». MITRE ATLAS es un mapa de tácticas y técnicas adversariales contra sistemas de IA, útil para red teamers y SOC. NIST AI RMF es un marco de gestión de riesgos de alto nivel para responsables de IA, alineado con gobernanza y cumplimiento. En auditoría real combinamos los tres: ATLAS para escenarios de ataque, OWASP para las verificaciones técnicas, NIST AI RMF para encajar el resultado con la gobernanza interna y el EU AI Act.
¿Cómo se hace red teaming a un LLM?
Se simula a un atacante autorizado contra el sistema completo: prompt injection directa e indirecta, jailbreaks, fuga del prompt de sistema, exfiltración de datos por contexto, escalada de privilegios mediante herramientas (function calling), envenenamiento de fuentes RAG y ataques multi-turno. La salida es una lista de hallazgos reproducibles con prueba de concepto y remediación priorizada por impacto. Importante: red teaming a un LLM no es un escaneo automático; requiere creatividad humana y conocimiento del dominio del sistema.
¿Qué herramientas open source existen para auditar la seguridad de un LLM?
Las más utilizadas son Garak (escáner de vulnerabilidades de NVIDIA con baterías de pruebas para jailbreaks, leakage y toxicity), PyRIT (framework de Microsoft para automatizar red teaming), promptfoo (testing de prompts y detecciones), Giskard (testing de calidad y robustez) y Rebuff (defensa contra prompt injection). Ninguna sustituye un red teaming manual; sirven para regresión continua y como complemento de la revisión humana.
¿Qué riesgos introduce darle herramientas a un agente IA?
Function calling y herramientas convierten al LLM en un sistema con efectos en el mundo: leer correo, escribir en una base de datos, hacer pagos, navegar webs. Cada herramienta extiende la superficie de ataque. Riesgos típicos: agencia excesiva (LLM09), confused deputy (la herramienta confía en el LLM más de lo prudente), encadenamiento de prompt injection (un correo malicioso que dispara una transferencia bancaria), permisos demasiado amplios y falta de aprobación humana en pasos sensibles. Mínimos exigibles: principio de mínimo privilegio por herramienta, allowlist de dominios, aprobación humana en operaciones irreversibles y registro auditable de cada llamada.
¿RAG es seguro por defecto? ¿Qué riesgos específicos tiene?
No, RAG no es seguro por defecto: introduce dos superficies adicionales sobre un LLM aislado. Una, prompt injection indirecta a través de los documentos recuperados — si tu base vectorial contiene un PDF malicioso, sus instrucciones llegan al modelo como si fueran del usuario. Dos, fugas de datos sensibles cuando el sistema recupera documentos a los que el usuario actual no debería tener acceso. Mitigaciones esenciales: control de acceso a nivel de documento aplicado en la query (no en el prompt), saneado de fuentes externas antes de indexar, etiquetado del origen de cada fragmento y precedencia de instrucciones del system prompt sobre las del contexto recuperado.
¿Es solo para producto en producción?
No. Funciona también para sistemas a punto de salir, prototipos avanzados o auditorías internas. Lo único que pedimos es que ya haya una arquitectura concreta para evaluar.
¿Qué pasa después de descargarlo?
Recibes el PDF en tu email. Si después de revisarlo quieres que pasemos las verificaciones sobre vuestro sistema concreto, ofrecemos un diagnóstico gratuito — basta con responder al email.